Mailinator is a popular disposable email service. It's also become a great tool for QA Teams to test email receipt, acknowledgment, authentication loops, and formatting. But in the beginning (um, wow - 15 years ago? really?) it was a tool to help people avoid spam.
Mailinator gets many millions of emails per day. At peak, it can be thousands of emails per second. Over time it has become ever more efficient at dealing with the deluge; processing, compressing, storing, and analyzing them. Once someone uses a Mailinator address, they tend to abandon it and use a different one next time. But the Internet never forgets. It seems like every Mailinator address ever used has found its way onto a marketing list somewhere.
Here's a picture of the last 6 days of email entering the system:
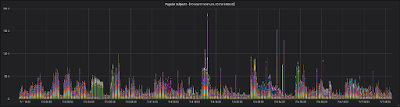 |
| Six days of frequent Subjects coming to Mailinator |
This graph (click on the image for a bigger version) shows a sub-set of email entering the Mailinator system. Each vertical bar represents a 10 minute interval. For each 10 minute interval, we count emails that have the same subject line that arrived 10 or more times. In each bar, a colored segment represents emails with a single subject line. Blasts of email that come as one-offs aren't on this graph, so this isn't so much a representation of Mailinator's total volume but more a segment of our flow that feels spammy.
Also, we're only selecting from email sent to the Public Mailinator system. Our subscribers get a separate, private (persistent) email system where they can send their test emails. None of those emails are represented here - and they wouldn't be anyway since they're not spam.
Look at that spike of 190k emails on July 4th at 12:40pm in the center of the graph. You also might notice that most of that line is one color (green). That shows the many tens of thousands of emails with the same subject line that Mailinator received in that 10 minute interval.
Consider also the corresponding graph:
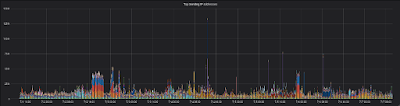 |
| Six days of sending IP addresses |
This graph shows the IP addresses that sent emails in the same time period. Notice that the spike is still there, but the graphs don't match up. Similarly to the first graph, only IP addresses that sent 10 emails within 10 minutes are on the graph. Except for a few spots, you don't really see the same incidence of colored bands. The IP addresses are far more spread out. The implication here is that many, many IP addresses are responsible for sending the same email to Mailinator. It's not uncommon to see thousands of IP addresses involved in one spam blast.
Even so, you can still see that spike at 7/4/2018 12:40pm. That was a company sending a 'marketing campaign' from one IP address. We won't mention who sent those (what they're doing isn't particularly interesting, and is far from unique), but it's likely that IP address was blacklisted in Gmail and other more discriminating email systems. Clearly, Mailinator isn't particularly discriminating.
Here's a closer look at the top graph:
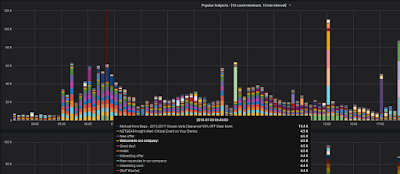 |
| Spam Campaign at 5am |
Here we've zoomed in on the "Top Subject Lines" graph for 7/5/2018 3:10am to 7/5/2018 8:47pm. The first thing we notice is that spammers are prompt! That campaign starts exactly at 5am.
Look at the overlay. From 6:40 to 6:50 we got just over 60,000 emails that fit our spammy profile. There are three spam campaigns listed. The first one is for Michael Kors Bags. Classic Style! 90% off! What a steal! Well, I'm sure they're very nice and convey an exclusive feeling. They sent our system 15,400 exclusive offers in that 10 minute interval.
Next in line looks to be (just guessing) a phishing campaign for people who might happen to have a Netgear router.
The third one is a combination of several subject lines all coming in around 4.4k, 4.5k, and 4.6k (if we mouse-over other intervals the Netgear campaign is all over the place, but this one is consistently 4.5k).
Notice we're highlighted on an email with the subject line "Welcome to our company:" Let's consider a graph that shows all the IP addresses that sent us an email with that subject line in that time interval - and we'll collect them all, not only the ones that sent 10 or more:
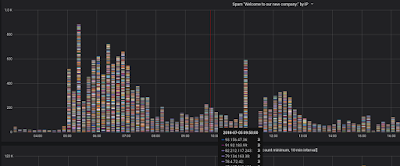 |
| One Email - thousands of Sending IPs |
So many different colors! Which means that it's a lot of different IP addresses.
Check out the mouseover for that 10 minute interval. For all those emails, the most we got from a single IP address was 3. That's a pretty well distributed spam network! Good job guys.
That email and it's siblings ("New offer", "Good day!", and "Hello!") are all part of the same campaign sent from many thousands of computers. From what we can see, it's being going on for more than a week.
For a while now, Mailinator has used this type of information to better store the emails that people are actually requesting. Remember, Mailinator doesn't have user accounts associated with inboxes.
The public inboxes here don't belong to anyone. The very nature of Mailinator is that inboxes are completely public. A fair characterization of our privacy policy here is: "At Mailinator, there is none!", and this is a good time to remind people that they should never send private information to Mailinator's public system (our FAQ used to say that if you sent super-sensitive private stuff here then you were a stupidhead - but now we're more polite).
[But still, please, don't do it]
We think we can help provide pretty good anonymity in some cases. The public system doesn't really want to know who you are.
Mailinator populates inboxes when email arrives. One way to think about our system is that all inboxes (trillions of them *) already exist, it's just that most aren't currently being used. Many users have found us to be a very handy tool for receiving a one-off email. More and more people are using us for email testing and that's very encouraging.
The sort of analysis we talk about here has helped us make some some useful and interesting architectural choices, and it has informed the way we deal with the enormous volume of email that Mailinator has evolved to receive.
It's also got us thinking - what sort of information lurks in data that flows our way every day? We have tools and a back-end infrastructure that allows a very fine-grained look at a really large volume of spam. Now that we have the ability, we're really excited to dig a little deeper into this pile of potted meat product.
Thanks for using Mailinator and keep sending it spam. It makes our graphs look pretty cool.
* It's actually much more than trillions. We looked at the RFCs, and with 64 characters in the <local-part> of an address, and the weird mix of rules for allowable characters, and even weirder rules for when and where some characters are and aren't allowed, it's a bit convoluted. But with a crayon and the back of an old envelope, we figure that a decent approximation is something like 2.4 x 10^111 inboxes for a domain.
If your crayon is sharper than ours, we'd love to hear your estimate.
Also, Mailinator can handle 212 characters in the <local-part> - which makes the number considerably larger.
You might need two crayons.









